Bayesian Linear Regression#
Welcome to this tutorial notebook that will go through the fitting and evaluation of Normative models with Bayesian Linear Regression (BLR).
Let’s jump right in.
Imports#
import warnings
import logging
import pandas as pd
import matplotlib.pyplot as plt
from pcntoolkit import (
BLR,
BsplineBasisFunction,
NormativeModel,
NormData,
load_fcon1000,
plot_centiles,
plot_centiles_advanced,
plot_qq,
plot_ridge,
)
import pcntoolkit.util.output
import seaborn as sns
sns.set_style("darkgrid")
# Suppress some annoying warnings and logs
pymc_logger = logging.getLogger("pymc")
pymc_logger.setLevel(logging.WARNING)
pymc_logger.propagate = False
warnings.simplefilter(action="ignore", category=FutureWarning)
pd.options.mode.chained_assignment = None # default='warn'
pcntoolkit.util.output.Output.set_show_messages(True)
Load data#
First we download a small example dataset from GitHub. We use the
open-source
fcon1000
dataset that is included in PCNtoolkit and can be loaded with one
command load_fcon1000().
This dataset contains derived structural MRI phenotypes from 1,078 subjects collected across 23 sites, including cortical thickness measures, subcortical and ventricular volumes, and global brain-volume estimates.
For this tutorial, we keep things simple and focus on one example
brain-related measure: the Right-Amygdala which is the volume of the
right amygdala, a deep brain structure.
# Download an example dataset
norm_data: NormData = load_fcon1000()
# Select only a few features
feature_to_model = [
"Right-Amygdala",
]
norm_data = norm_data.sel({"response_vars": feature_to_model})
# Split into train and test sets
train, test = norm_data.train_test_split()
Process: 29780 - 2026-04-22 16:03:16 - Removed 0 NANs
Process: 29780 - 2026-04-22 16:03:16 - Dataset "fcon1000" created.
- 1078 observations
- 1078 unique subjects
- 1 covariates
- 217 response variables
- 2 batch effects:
sex (2)
site (23)
# Visualize the data
feature_to_plot = feature_to_model[0]
df = train.to_dataframe()
fig, ax = plt.subplots(1, 2, figsize=(15, 5))
sns.countplot(data=df, y=("batch_effects", "site"), hue=("batch_effects", "sex"), ax=ax[0], orient="h")
ax[0].legend(title="Sex")
ax[0].set_title("Count of sites")
ax[0].set_xlabel("Site")
ax[0].set_ylabel("Count")
sns.scatterplot(
data=df,
x=("X", "age"),
y=("Y", feature_to_plot),
hue=("batch_effects", "site"),
style=("batch_effects", "sex"),
ax=ax[1],
)
ax[1].legend([], [])
ax[1].set_title(f"Scatter plot of age vs {feature_to_plot}")
ax[1].set_xlabel("Age")
ax[1].set_ylabel(feature_to_plot)
plt.show()
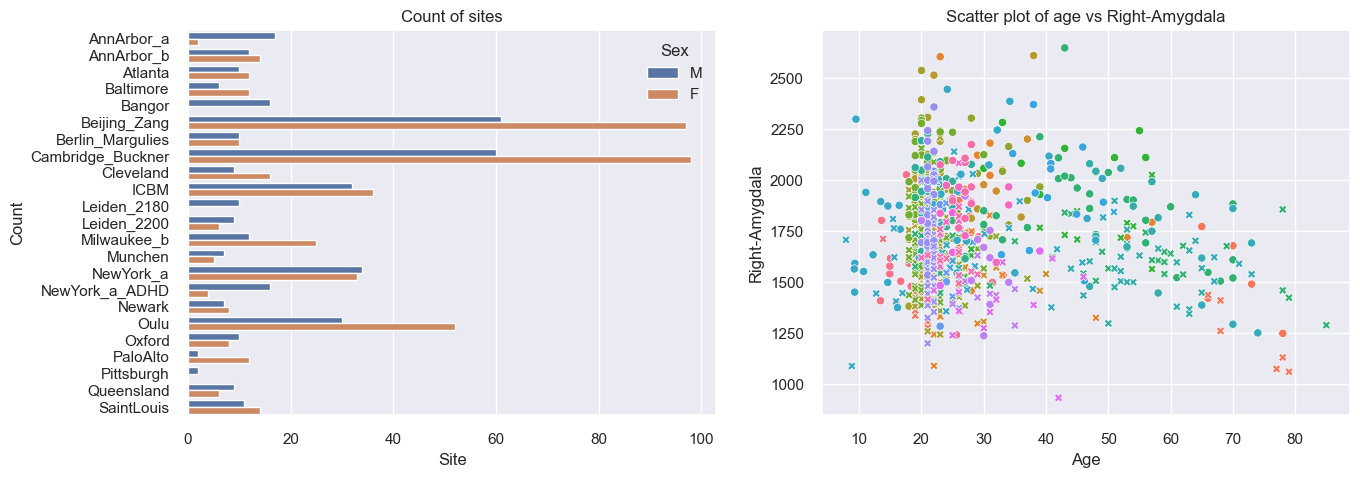
The left diagram shows some sites contain more subjects than others, e.g., the biggest sites are in Beijing and Cambridge. The right diagram shows that most of the subject are between 20 and 30 years old.
Normative model: BLR#
A normative model consists of a regression model for each response variable. Two examples of regressions models you can use with PCNtoolkit are the Bayesian Linear Regression (BLR) and Hierarchical Bayesian Regression (HBR) models. For this tutorial we select the BLR.
The BLR class has a number of parameters that can be set. At first,
we choose a simple BLR model with a B-spline basis function
template_blr = BLR(
name="template",
# We use a B-spline basis expansion for the mean, so the predicted mean is a smooth function of the covariates
basis_function_mean=BsplineBasisFunction(degree=3, nknots=5),
# We want the variance to be a function of the covariates
heteroskedastic=True
)
After specifying the regression model, we can configure a normative model.
A normative model has a number of configuration options:
savemodel: Whether to save the model after fitting. It creates a JSON file containing your trained model parameters. This is useful to:Avoid re-fitting: Load the saved model later instead of training from scratch every time.
Share with collaborators: Send the file to colleagues, who can update it with their own data, producing a better model trained on more data combined. We will cover this in the federated learning tutorial.
evaluate_model: Whether to evaluate the model after fitting. It computes a set of metrics are computed that tell you how well your model fits the data. For more information, see our evaluation metrics tutorial.saveresults: Whether to save the per-subject results after predicting. Results include:how far the observed value for this subject is from the fitted model’s predicted typical value for someone with similar covariates and batch effects (
Z)how statistically surprising the observed value for this subject is under the fitted model’s predicted distribution (
logp).fitted model’s predicted distribution at selected centiles (such as the 5th, 50th, and 95th centiles) for this subject (
centiles)summary of evaluation metrics for each response variable, when
evaluate_modelis enabled.
saveplots: Whether to save the plots after fitting.save_dir: The directory to save the model, results, and plots.inscaler: The scaler to use for the input data. Can be either one of “standardize”, “minmax”, “robminmax”, “none”outscaler: The scaler to use for the output data. Can be either one of “standardize”, “minmax”, “robminmax”, “none”
model = NormativeModel(
template_regression_model=template_blr, # we select our BLR model
savemodel=False, # we dont need to save the model for this tutorial
evaluate_model=True, # we want to evaluate the model to see how well it fits the data
saveresults=False, # we don't need to save the results for this tutorial
saveplots=False,
save_dir="resources/blr/save_dir",
inscaler="standardize",
outscaler="standardize",
)
Fit the model#
With all that configured, we can fit the model.
The fit_predict function will fit the model, evaluate it, and save
the results and plots (if so configured).
After that, it will compute Z-scores and centiles for the test set.
All results can be found in the save directory.
model.fit_predict(train, test);
Process: 29780 - 2026-04-22 16:03:16 - Fitting models on 1 response variables.
Process: 29780 - 2026-04-22 16:03:16 - Fitting model for Right-Amygdala.
Process: 29780 - 2026-04-22 16:03:16 - Making predictions on 1 response variables.
Process: 29780 - 2026-04-22 16:03:16 - Computing z-scores for 1 response variables.
Process: 29780 - 2026-04-22 16:03:16 - Computing z-scores for Right-Amygdala.
Process: 29780 - 2026-04-22 16:03:16 - Computing centiles for 1 response variables.
Process: 29780 - 2026-04-22 16:03:16 - Computing centiles for Right-Amygdala.
Process: 29780 - 2026-04-22 16:03:16 - Computing log-probabilities for 1 response variables.
Process: 29780 - 2026-04-22 16:03:16 - Computing log-probabilities for 1 response variables.
Process: 29780 - 2026-04-22 16:03:16 - Computing log-probabilities for Right-Amygdala.
Process: 29780 - 2026-04-22 16:03:16 - Computing yhat for 1 response variables.
Process: 29780 - 2026-04-22 16:03:16 - Computing yhat for Right-Amygdala.
Process: 29780 - 2026-04-22 16:03:17 - Making predictions on 1 response variables.
Process: 29780 - 2026-04-22 16:03:17 - Computing z-scores for 1 response variables.
Process: 29780 - 2026-04-22 16:03:17 - Computing z-scores for Right-Amygdala.
Process: 29780 - 2026-04-22 16:03:17 - Computing centiles for 1 response variables.
Process: 29780 - 2026-04-22 16:03:17 - Computing centiles for Right-Amygdala.
Process: 29780 - 2026-04-22 16:03:17 - Computing log-probabilities for 1 response variables.
Process: 29780 - 2026-04-22 16:03:17 - Computing log-probabilities for 1 response variables.
Process: 29780 - 2026-04-22 16:03:17 - Computing log-probabilities for Right-Amygdala.
Process: 29780 - 2026-04-22 16:03:17 - Computing yhat for 1 response variables.
Process: 29780 - 2026-04-22 16:03:17 - Computing yhat for Right-Amygdala.
Looking at the printed messages, we can identify three main steps:
- “Fitting models on 1 response variables.”The model is being fitted on the training data.
- “Making predictions on 1 response variables.”First, PCNtoolkit computes predictions on the training data.
- “Making predictions on 1 response variables.”Then, PCNtoolkit computes predictions on the test data
Plot the results#
The PCNtoolkit offers some basic plotting functions:
plot_centiles: Plot the predicted centiles for a modelplot_qq: Plot the QQ-plot of the predicted Z-scores
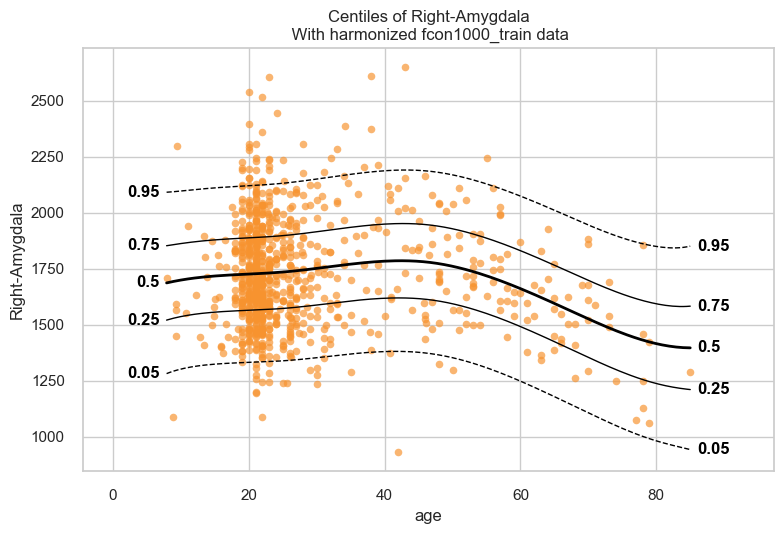
Let’s start with the centiles plot:
plot_centiles(model, scatter_data=train);
Process: 29780 - 2026-04-22 16:03:17 - Dataset "centile" created.
- 150 observations
- 150 unique subjects
- 1 covariates
- 1 response variables
- 2 batch effects:
sex (1)
site (1)
Process: 29780 - 2026-04-22 16:03:17 - Computing centiles for 1 response variables.
Process: 29780 - 2026-04-22 16:03:17 - Computing centiles for Right-Amygdala.
Process: 29780 - 2026-04-22 16:03:17 - Harmonizing data on 1 response variables.
Process: 29780 - 2026-04-22 16:03:17 - Harmonizing data for Right-Amygdala.
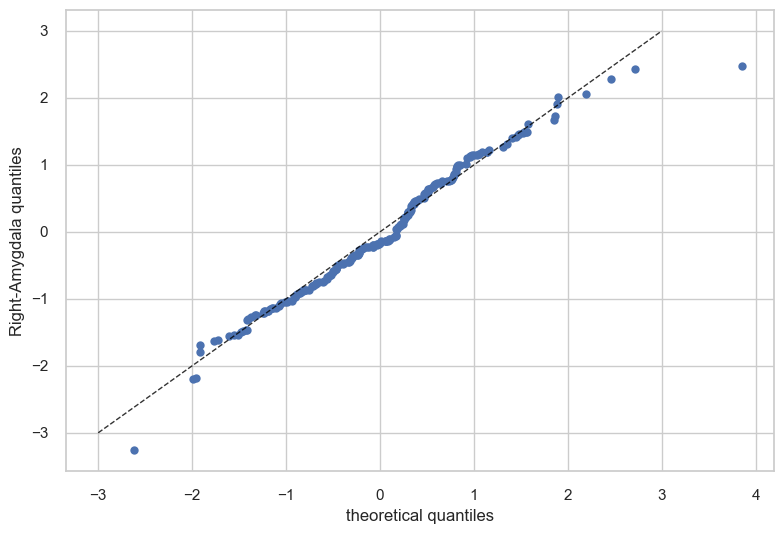
Now let’s see the qq plots
plot_qq(test, plot_id_line=True);
Evaluation statistics#
Evaluation statistcs are stored in the NormData object. There is a
separate tutorial for detailed explanations of each metric.
# Show the evaluation metrics from the train set
display(train.get_statistics_df())
# Show the evaluation metrics from the train set
display(test.get_statistics_df())
| statistic | EXPV | MACE | MAPE | MSLL | NLL | R2 | RMSE | Rho | Rho_p | SMSE | ShapiroW |
|---|---|---|---|---|---|---|---|---|---|---|---|
| response_vars | |||||||||||
| Right-Amygdala | 0.050108 | 0.014153 | 0.112855 | -0.025123 | 1.393816 | 0.050108 | 238.782623 | 0.103329 | 0.002386 | 0.949892 | 0.989231 |
| statistic | EXPV | MACE | MAPE | MSLL | NLL | R2 | RMSE | Rho | Rho_p | SMSE | ShapiroW |
|---|---|---|---|---|---|---|---|---|---|---|---|
| response_vars | |||||||||||
| Right-Amygdala | 0.023886 | 0.022778 | 0.115624 | -0.009888 | 1.371381 | 0.023159 | 233.194296 | 0.061853 | 0.365652 | 0.976841 | 0.991958 |
Normative model: warped-BLR with batch effects#
Now we fit a more flexible BLR model. Compared with the previous model, this version does two extra things.
First, it uses a warp. The warp lets the model handle response distributions that are non-Gaussian, for example when the data are skewed or have heavier tails.
Find more information about the warped-BLR (w-BLR) on this paper: > Fraza, C. J., Dinga, R., Beckmann, C. F., & Marquand, A. F. (2021). Warped Bayesian linear regression for normative modelling of big data. NeuroImage, 245, 118715. https://doi.org/10.1016/j.neuroimage.2021.118715
Second, it models batch effects. Here, the batches are variables such as site and sex. Adding batch effects lets the model account for systematic differences between groups, instead of forcing all groups to follow exactly the same mean and variance patterns.
warped_blr = BLR(
name="template",
# We use a B-spline basis expansion for the mean, so the predicted mean is a smooth function of the covariates
basis_function_mean=BsplineBasisFunction(degree=3, nknots=5),
# We want the variance to be a function of the covariates
heteroskedastic=True,
# Allow warping
warp_name="warpsinharcsinh", # We configure a sinh-arcsinh warp
# Model the batch effects (sex and site)
fixed_effect=True, # We model offsets in the mean for each individual batch effect
fixed_effect_slope=True, # We model a fixed effect in the slope of the mean for each individual batch effect
fixed_effect_var_slope=True, # We model a fixed effect in the slope of the variance for each individual batch effect
)
model = NormativeModel(
template_regression_model=warped_blr, # we select our w-BLR model
savemodel=False, # we dont need to save the model for this tutorial
evaluate_model=True, # we want to evaluate the model to see how well it fits the data
saveresults=False, # we don't need to save the results for this tutorial
saveplots=False,
save_dir="resources/blr/save_dir",
inscaler="standardize",
outscaler="standardize",
)
Fit the model#
model.fit_predict(train, test);
Process: 29780 - 2026-04-22 16:03:17 - Fitting models on 1 response variables.
Process: 29780 - 2026-04-22 16:03:17 - Fitting model for Right-Amygdala.
C:UserskontsiDocumentsGitHubPCNtoolkit-localpcntoolkitregression_modelblr.py:695: LinAlgWarning: An ill-conditioned matrix detected: slice 0 has rcond = 2.1632854141299013e-41. invAXt: np.ndarray = linalg.solve(self.A, X.T, check_finite=False) C:UserskontsiDocumentsGitHubPCNtoolkit-localpcntoolkitutiloutput.py:266: UserWarning: Process: 29780 - 2026-04-22 16:03:19 - Posterior estimation failed: Matrix is not positive definite. The optimizer could not find a stable solution. Retrying optimization. warnings.warn(message) C:UserskontsiDocumentsGitHubPCNtoolkit-localpcntoolkitregression_modelblr.py:695: LinAlgWarning: An ill-conditioned matrix detected: slice 0 has rcond = 2.95672596274763e-41. invAXt: np.ndarray = linalg.solve(self.A, X.T, check_finite=False) C:UserskontsiDocumentsGitHubPCNtoolkit-localpcntoolkitregression_modelblr.py:695: LinAlgWarning: An ill-conditioned matrix detected: slice 0 has rcond = 2.383412485561854e-41. invAXt: np.ndarray = linalg.solve(self.A, X.T, check_finite=False) C:UserskontsiDocumentsGitHubPCNtoolkit-localpcntoolkitregression_modelblr.py:695: LinAlgWarning: An ill-conditioned matrix detected: slice 0 has rcond = 1.5435195683709543e-41. invAXt: np.ndarray = linalg.solve(self.A, X.T, check_finite=False) C:UserskontsiDocumentsGitHubPCNtoolkit-localpcntoolkitregression_modelblr.py:695: LinAlgWarning: An ill-conditioned matrix detected: slice 0 has rcond = 4.143933578597161e-41. invAXt: np.ndarray = linalg.solve(self.A, X.T, check_finite=False) C:UserskontsiDocumentsGitHubPCNtoolkit-localpcntoolkitregression_modelblr.py:695: LinAlgWarning: An ill-conditioned matrix detected: slice 0 has rcond = 2.163285543871327e-41. invAXt: np.ndarray = linalg.solve(self.A, X.T, check_finite=False) C:UserskontsiDocumentsGitHubPCNtoolkit-localpcntoolkitregression_modelblr.py:695: LinAlgWarning: An ill-conditioned matrix detected: slice 0 has rcond = 2.140576045606065e-41. invAXt: np.ndarray = linalg.solve(self.A, X.T, check_finite=False) C:UserskontsiDocumentsGitHubPCNtoolkit-localpcntoolkitregression_modelblr.py:695: LinAlgWarning: An ill-conditioned matrix detected: slice 0 has rcond = 2.1632853629035901e-41. invAXt: np.ndarray = linalg.solve(self.A, X.T, check_finite=False) C:UserskontsiDocumentsGitHubPCNtoolkit-localpcntoolkitregression_modelblr.py:695: LinAlgWarning: An ill-conditioned matrix detected: slice 0 has rcond = 2.1632855727422735e-41. invAXt: np.ndarray = linalg.solve(self.A, X.T, check_finite=False) C:UserskontsiDocumentsGitHubPCNtoolkit-localpcntoolkitregression_modelblr.py:695: LinAlgWarning: An ill-conditioned matrix detected: slice 0 has rcond = 2.1632855729300712e-41. invAXt: np.ndarray = linalg.solve(self.A, X.T, check_finite=False) C:UserskontsiDocumentsGitHubPCNtoolkit-localpcntoolkitregression_modelblr.py:695: LinAlgWarning: An ill-conditioned matrix detected: slice 0 has rcond = 2.1632854929817363e-41. invAXt: np.ndarray = linalg.solve(self.A, X.T, check_finite=False) C:UserskontsiDocumentsGitHubPCNtoolkit-localpcntoolkitregression_modelblr.py:695: LinAlgWarning: An ill-conditioned matrix detected: slice 0 has rcond = 2.16328555742483e-41. invAXt: np.ndarray = linalg.solve(self.A, X.T, check_finite=False) C:UserskontsiDocumentsGitHubPCNtoolkit-localpcntoolkitregression_modelblr.py:695: LinAlgWarning: An ill-conditioned matrix detected: slice 0 has rcond = 2.163286153217964e-41. invAXt: np.ndarray = linalg.solve(self.A, X.T, check_finite=False) C:UserskontsiDocumentsGitHubPCNtoolkit-localpcntoolkitregression_modelblr.py:695: LinAlgWarning: An ill-conditioned matrix detected: slice 0 has rcond = 2.1632854859222148e-41. invAXt: np.ndarray = linalg.solve(self.A, X.T, check_finite=False) C:UserskontsiDocumentsGitHubPCNtoolkit-localpcntoolkitregression_modelblr.py:695: LinAlgWarning: An ill-conditioned matrix detected: slice 0 has rcond = 2.1632855290078173e-41. invAXt: np.ndarray = linalg.solve(self.A, X.T, check_finite=False) C:UserskontsiDocumentsGitHubPCNtoolkit-localpcntoolkitregression_modelblr.py:695: LinAlgWarning: An ill-conditioned matrix detected: slice 0 has rcond = 2.1632856376007886e-41. invAXt: np.ndarray = linalg.solve(self.A, X.T, check_finite=False) C:UserskontsiDocumentsGitHubPCNtoolkit-localpcntoolkitregression_modelblr.py:695: LinAlgWarning: An ill-conditioned matrix detected: slice 0 has rcond = 2.9792786990864296e-41. invAXt: np.ndarray = linalg.solve(self.A, X.T, check_finite=False) C:UserskontsiDocumentsGitHubPCNtoolkit-localpcntoolkitregression_modelblr.py:695: LinAlgWarning: An ill-conditioned matrix detected: slice 0 has rcond = 2.163285466903053e-41. invAXt: np.ndarray = linalg.solve(self.A, X.T, check_finite=False) C:UserskontsiDocumentsGitHubPCNtoolkit-localpcntoolkitregression_modelblr.py:695: LinAlgWarning: An ill-conditioned matrix detected: slice 0 has rcond = 2.163285476309751e-41. invAXt: np.ndarray = linalg.solve(self.A, X.T, check_finite=False) C:UserskontsiDocumentsGitHubPCNtoolkit-localpcntoolkitregression_modelblr.py:695: LinAlgWarning: An ill-conditioned matrix detected: slice 0 has rcond = 2.1632854952020879e-41. invAXt: np.ndarray = linalg.solve(self.A, X.T, check_finite=False) C:UserskontsiDocumentsGitHubPCNtoolkit-localpcntoolkitregression_modelblr.py:695: LinAlgWarning: An ill-conditioned matrix detected: slice 0 has rcond = 2.1632854263350986e-41. invAXt: np.ndarray = linalg.solve(self.A, X.T, check_finite=False) C:UserskontsiDocumentsGitHubPCNtoolkit-localpcntoolkitregression_modelblr.py:695: LinAlgWarning: An ill-conditioned matrix detected: slice 0 has rcond = 2.163285567139869e-41. invAXt: np.ndarray = linalg.solve(self.A, X.T, check_finite=False) C:UserskontsiDocumentsGitHubPCNtoolkit-localpcntoolkitregression_modelblr.py:695: LinAlgWarning: An ill-conditioned matrix detected: slice 0 has rcond = 2.163285569343776e-41. invAXt: np.ndarray = linalg.solve(self.A, X.T, check_finite=False) C:UserskontsiDocumentsGitHubPCNtoolkit-localpcntoolkitregression_modelblr.py:695: LinAlgWarning: An ill-conditioned matrix detected: slice 0 has rcond = 2.1632855393099296e-41. invAXt: np.ndarray = linalg.solve(self.A, X.T, check_finite=False) C:UserskontsiDocumentsGitHubPCNtoolkit-localpcntoolkitregression_modelblr.py:695: LinAlgWarning: An ill-conditioned matrix detected: slice 0 has rcond = 2.1632855739716668e-41. invAXt: np.ndarray = linalg.solve(self.A, X.T, check_finite=False) C:UserskontsiDocumentsGitHubPCNtoolkit-localpcntoolkitregression_modelblr.py:695: LinAlgWarning: An ill-conditioned matrix detected: slice 0 has rcond = 1.957421929942335e-41. invAXt: np.ndarray = linalg.solve(self.A, X.T, check_finite=False)
Process: 29780 - 2026-04-22 16:03:19 - Making predictions on 1 response variables.
Process: 29780 - 2026-04-22 16:03:19 - Computing z-scores for 1 response variables.
Process: 29780 - 2026-04-22 16:03:19 - Computing z-scores for Right-Amygdala.
Process: 29780 - 2026-04-22 16:03:19 - Computing centiles for 1 response variables.
Process: 29780 - 2026-04-22 16:03:19 - Computing centiles for Right-Amygdala.
Process: 29780 - 2026-04-22 16:03:19 - Computing log-probabilities for 1 response variables.
Process: 29780 - 2026-04-22 16:03:19 - Computing log-probabilities for 1 response variables.
Process: 29780 - 2026-04-22 16:03:19 - Computing log-probabilities for Right-Amygdala.
Process: 29780 - 2026-04-22 16:03:19 - Computing yhat for 1 response variables.
Process: 29780 - 2026-04-22 16:03:19 - Computing yhat for Right-Amygdala.
Process: 29780 - 2026-04-22 16:03:19 - Making predictions on 1 response variables.
Process: 29780 - 2026-04-22 16:03:19 - Computing z-scores for 1 response variables.
Process: 29780 - 2026-04-22 16:03:19 - Computing z-scores for Right-Amygdala.
Process: 29780 - 2026-04-22 16:03:19 - Computing centiles for 1 response variables.
Process: 29780 - 2026-04-22 16:03:19 - Computing centiles for Right-Amygdala.
Process: 29780 - 2026-04-22 16:03:19 - Computing log-probabilities for 1 response variables.
Process: 29780 - 2026-04-22 16:03:19 - Computing log-probabilities for 1 response variables.
Process: 29780 - 2026-04-22 16:03:19 - Computing log-probabilities for Right-Amygdala.
Process: 29780 - 2026-04-22 16:03:19 - Computing yhat for 1 response variables.
Process: 29780 - 2026-04-22 16:03:19 - Computing yhat for Right-Amygdala.
Plot the results#
Centiles plot#
Because this model includes batch effects, we can now visualize results not only over all data, but also separately for specific groups such as sites or sexes.
Below we show a few useful options: plot_centiles_advanced to
highlight specific batch effects in the plot, plot_qq to inspect
model fit by batch effects, and plot_ridge to compare the
distribution of responses or Z-scores across batch effects.
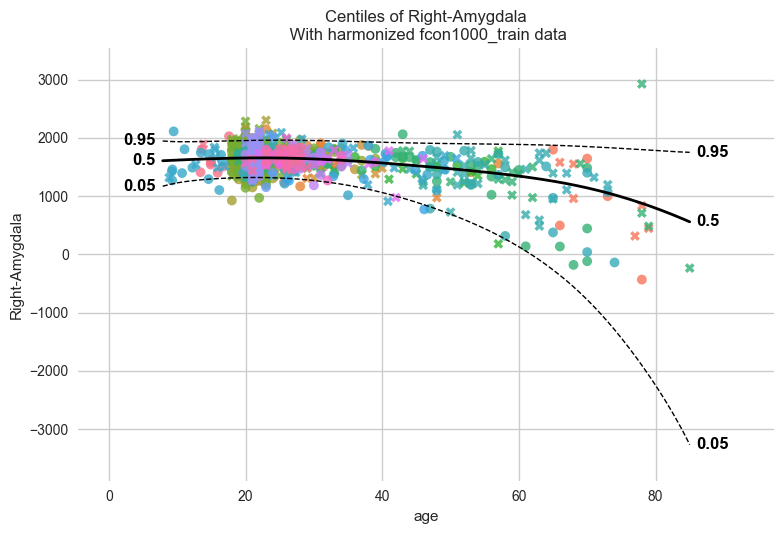
plot_centiles_advanced(
model,
scatter_data=train,
# Plot these centiles, the default is [0.05, 0.25, 0.5, 0.75, 0.95]
centiles=[0.05, 0.5, 0.95],
# Highlight a specific gender from specific sites
batch_effects={"site": [ "Beijing_Zang", "AnnArbor_a",], "sex": ["M"]},
# Show other data not belonging to the groups above
show_other_data=True,
# Harmonize the scatterdata, this means that we 'remove' the batch effects from the data, by simulating what the data would have looked like if all data was from the same batch.
harmonize_data=True
);
Process: 29780 - 2026-04-22 16:03:19 - Dataset "centile" created.
- 150 observations
- 150 unique subjects
- 1 covariates
- 1 response variables
- 2 batch effects:
site (1)
sex (1)
Process: 29780 - 2026-04-22 16:03:19 - Computing centiles for 1 response variables.
Process: 29780 - 2026-04-22 16:03:19 - Computing centiles for Right-Amygdala.
Process: 29780 - 2026-04-22 16:03:19 - Harmonizing data on 1 response variables.
Process: 29780 - 2026-04-22 16:03:19 - Harmonizing data for Right-Amygdala.
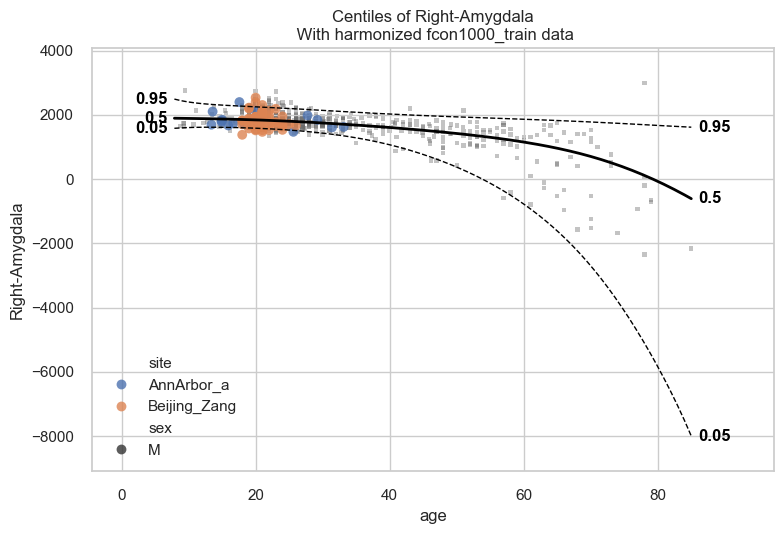
When we call plot_centiles_advanced, the function prints messages
such as Computing centiles and Harmonizing data for Right-Amygdala.
These messages appear because the plot also computes centiles and
harmonize the data for based on the batch effects that you selected in
the function call (see batch_effects keyword argument).
Exercise Set
batch_effects='all'inplot_centiles_advanced. How does that affect your plotted centiles and scatter data?
Inspecting the centiles plot#
From the previous plot we see the fit is not good. In particular, the
0.05 centile and even the 0.5 centile can become negative, even though
the response variable here, Right-Amygdala, is a volume and
therefore should remain positive.
A likely reason is that this model is not the right one for this dataset. Our dataset is very heterogeneous: it contains very uneven site sizes, several very small sites, and sites that cover different and sometimes narrow age ranges (see the cell in the beginning of this notebook where we visualise the data). As a result modelling each batch effect separately in our w-BLR does not necessarily improve the model.
This is a useful reminder that a more flexible model is not always a better model. For this dataset, the simpler BLR model used earlier appears to fit better than this more complex w-BLR with batch effects. It is important to understand your data before you select a model.
Exercise Try a few alternative model configurations and compare them.
For example, keep the warped-BLR but remove the modelling of the batch effects and then compare it with the simpler BLR model from the first part of the notebook. For the comparison you can use the centile plots, QQ plots, or the evaluation metrics to decide which model fits this dataset better.
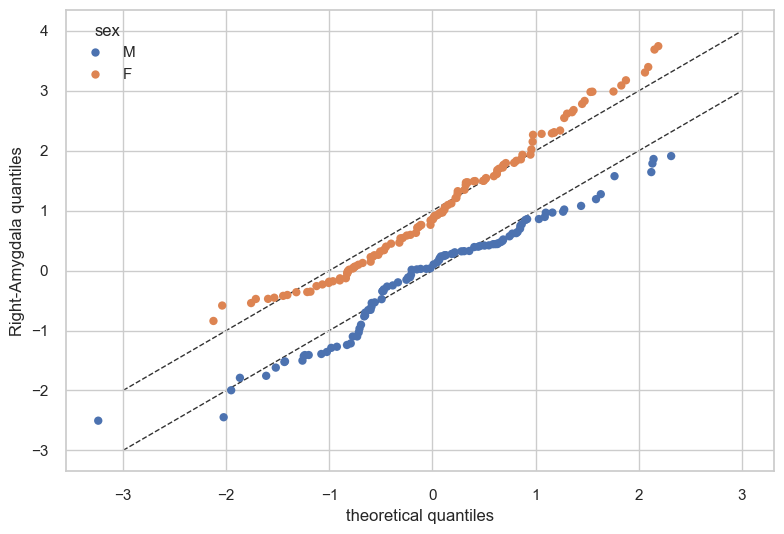
QQ-plot and ridge plot#
Finally, we show how we can use plot_qq and plot_ridge:
# Show the qq-plot per sex
plot_qq(test, plot_id_line=True, hue_data="sex", split_data="sex")
sns.set_theme(style="darkgrid", rc={"axes.facecolor": (0, 0, 0, 0)})
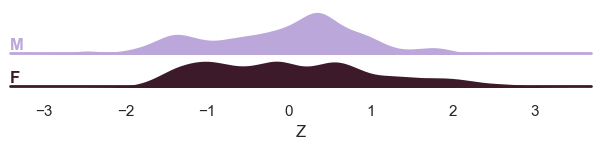
# Show the ridge plot per sex
plot_ridge(test, "Z", split_by="sex");
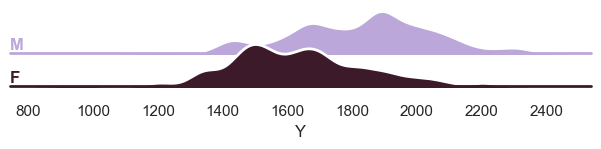
# We can also show the 'Y' variable
plot_ridge(test, "Y", split_by="sex");
c:UserskontsiAppDataLocalanaconda3envs.ptk-devLibsite-packagesseabornaxisgrid.py:123: UserWarning: Tight layout not applied. tight_layout cannot make Axes height small enough to accommodate all Axes decorations. self._figure.tight_layout(*args, **kwargs) c:UserskontsiAppDataLocalanaconda3envs.ptk-devLibsite-packagesseabornaxisgrid.py:123: UserWarning: Tight layout not applied. The bottom and top margins cannot be made large enough to accommodate all Axes decorations. self._figure.tight_layout(*args, **kwargs) c:UserskontsiAppDataLocalanaconda3envs.ptk-devLibsite-packagesseabornaxisgrid.py:123: UserWarning: Tight layout not applied. The bottom and top margins cannot be made large enough to accommodate all Axes decorations. self._figure.tight_layout(*args, **kwargs) c:UserskontsiAppDataLocalanaconda3envs.ptk-devLibsite-packagesseabornaxisgrid.py:123: UserWarning: Tight layout not applied. The bottom and top margins cannot be made large enough to accommodate all Axes decorations. self._figure.tight_layout(*args, **kwargs) c:UserskontsiAppDataLocalanaconda3envs.ptk-devLibsite-packagesseabornaxisgrid.py:123: UserWarning: Tight layout not applied. The bottom and top margins cannot be made large enough to accommodate all Axes decorations. self._figure.tight_layout(*args, **kwargs) C:UserskontsiDocumentsGitHubPCNtoolkit-localpcntoolkitutilplotter.py:1045: UserWarning: Tight layout not applied. tight_layout cannot make Axes height small enough to accommodate all Axes decorations. g.figure.tight_layout()
c:UserskontsiAppDataLocalanaconda3envs.ptk-devLibsite-packagesseabornaxisgrid.py:123: UserWarning: Tight layout not applied. tight_layout cannot make Axes height small enough to accommodate all Axes decorations. self._figure.tight_layout(*args, **kwargs) c:UserskontsiAppDataLocalanaconda3envs.ptk-devLibsite-packagesseabornaxisgrid.py:123: UserWarning: Tight layout not applied. The bottom and top margins cannot be made large enough to accommodate all Axes decorations. self._figure.tight_layout(*args, **kwargs) c:UserskontsiAppDataLocalanaconda3envs.ptk-devLibsite-packagesseabornaxisgrid.py:123: UserWarning: Tight layout not applied. The bottom and top margins cannot be made large enough to accommodate all Axes decorations. self._figure.tight_layout(*args, **kwargs) c:UserskontsiAppDataLocalanaconda3envs.ptk-devLibsite-packagesseabornaxisgrid.py:123: UserWarning: Tight layout not applied. The bottom and top margins cannot be made large enough to accommodate all Axes decorations. self._figure.tight_layout(*args, **kwargs) c:UserskontsiAppDataLocalanaconda3envs.ptk-devLibsite-packagesseabornaxisgrid.py:123: UserWarning: Tight layout not applied. The bottom and top margins cannot be made large enough to accommodate all Axes decorations. self._figure.tight_layout(*args, **kwargs) C:UserskontsiDocumentsGitHubPCNtoolkit-localpcntoolkitutilplotter.py:1045: UserWarning: Tight layout not applied. tight_layout cannot make Axes height small enough to accommodate all Axes decorations. g.figure.tight_layout()
What’s next?#
Now we have a normative Bayesian linear regression model, we can use it to:
- Make predictions on new data
- Harmonize data, this means that we ‘remove’ the batch effects from the
data, by simulating what the data would have looked like if all data was from the same batch.
Synthesize new data
Predicting#
model.predict(test);
Process: 29780 - 2026-04-22 16:03:21 - Making predictions on 1 response variables.
Process: 29780 - 2026-04-22 16:03:21 - Computing z-scores for 1 response variables.
Process: 29780 - 2026-04-22 16:03:21 - Computing z-scores for Right-Amygdala.
Process: 29780 - 2026-04-22 16:03:21 - Computing centiles for 1 response variables.
Process: 29780 - 2026-04-22 16:03:21 - Computing centiles for Right-Amygdala.
Process: 29780 - 2026-04-22 16:03:21 - Computing log-probabilities for 1 response variables.
Process: 29780 - 2026-04-22 16:03:21 - Computing log-probabilities for 1 response variables.
Process: 29780 - 2026-04-22 16:03:21 - Computing log-probabilities for Right-Amygdala.
Process: 29780 - 2026-04-22 16:03:21 - Computing yhat for 1 response variables.
Process: 29780 - 2026-04-22 16:03:21 - Computing yhat for Right-Amygdala.
Harmonize#
# Harmonizing is also easy:
reference_batch_effect = {
"site": "Beijing_Zang",
"sex": "M",
} # Set a pseudo-batch effect. I.e., this means 'pretend that all data was from this site and sex'
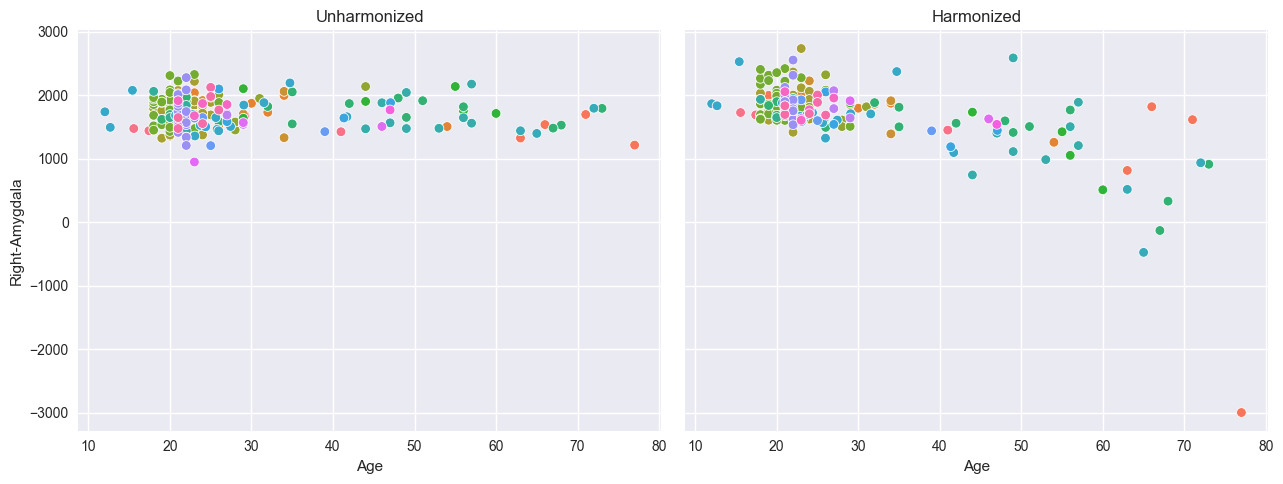
model.harmonize(test, reference_batch_effect=reference_batch_effect) # <- easy
plt.style.use("seaborn-v0_8")
df = test.to_dataframe()
fig, ax = plt.subplots(1, 2, figsize=(13, 5), sharey=True)
sns.scatterplot(data=df, x=("X", "age"), y=("Y", feature_to_plot), hue=("batch_effects", "site"), ax=ax[0])
sns.scatterplot(data=df, x=("X", "age"), y=("Y_harmonized", feature_to_plot), hue=("batch_effects", "site"), ax=ax[1])
ax[0].title.set_text("Unharmonized")
ax[1].title.set_text("Harmonized")
ax[0].legend([], [])
ax[1].legend([], [])
ax[0].set_xlabel("Age")
ax[0].set_ylabel(feature_to_plot)
ax[1].set_xlabel("Age")
ax[1].set_ylabel(feature_to_plot)
plt.tight_layout()
plt.show()
Process: 29780 - 2026-04-22 16:03:21 - Harmonizing data on 1 response variables.
Process: 29780 - 2026-04-22 16:03:21 - Harmonizing data for Right-Amygdala.
Synthesize#
Our models can synthesize new data that follows the learned distribution.
Not only the distribution of the response variables given a covariate is learned, but also the ranges of the covariates within each batch effect. So if we have fitted a model on a number of sites, and subjects from A have an age between 10 and 20, then the synthesized pseudo-subjects from site A will also have an age between 10 and 20.
Not only that, but we also sample the batch effects in the frequency of the batch effects in the original data. So if the train data contained twice as many subjects from site A as site B, then the synthesized pseudo-subjects will also have twice as many subjects from site A as site B.
# Generate 10000 synthetic datapoints from scratch
synthetic_data = model.synthesize(covariate_range_per_batch_effect=True, n_samples=10000) # <- also easy
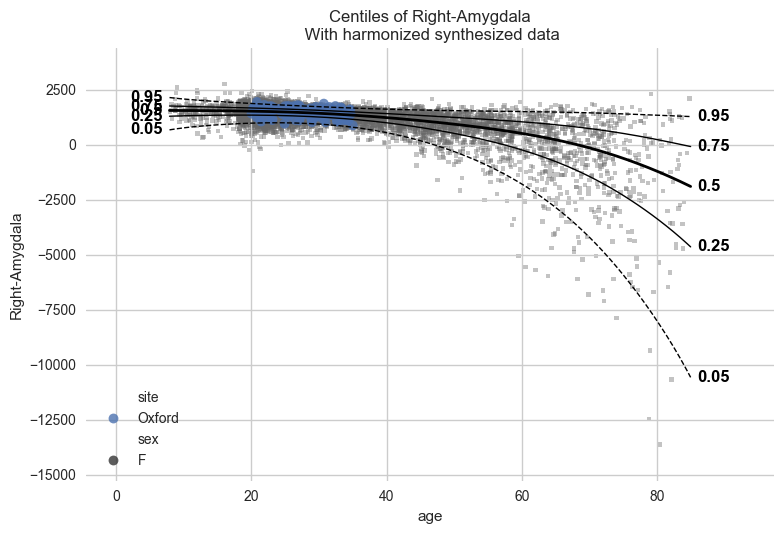
plot_centiles_advanced(
model,
covariate="age", # Which covariate to plot on the x-axis
scatter_data=synthetic_data,
show_other_data=True,
harmonize_data=True,
show_legend=True,
);
Process: 29780 - 2026-04-22 16:03:25 - Dataset "synthesized" created.
- 10000 observations
- 10000 unique subjects
- 1 covariates
- 1 response variables
- 2 batch effects:
sex (2)
site (23)
Process: 29780 - 2026-04-22 16:03:25 - Synthesizing data for 1 response variables.
Process: 29780 - 2026-04-22 16:03:25 - Synthesizing data for Right-Amygdala.
Process: 29780 - 2026-04-22 16:03:25 - Dataset "centile" created.
- 150 observations
- 150 unique subjects
- 1 covariates
- 1 response variables
- 2 batch effects:
sex (1)
site (1)
Process: 29780 - 2026-04-22 16:03:25 - Computing centiles for 1 response variables.
Process: 29780 - 2026-04-22 16:03:25 - Computing centiles for Right-Amygdala.
Process: 29780 - 2026-04-22 16:03:25 - Harmonizing data on 1 response variables.
Process: 29780 - 2026-04-22 16:03:25 - Harmonizing data for Right-Amygdala.
# Synthesize new Y data for existing X data
new_test_data = test.copy()
# Remove the Y data, this way we will synthesize new Y data for the existing X data
if hasattr(new_test_data, "Y"):
del new_test_data["Y"]
synthetic = model.synthesize(new_test_data) # <- will fill in the missing Y data
plot_centiles_advanced(
model,
centiles=[0.05, 0.5, 0.95], # Plot arbitrary centiles
covariate="age", # Which covariate to plot on the x-axis
scatter_data=train, # Scatter the train data points
batch_effects="all", # You can set this to "all" to show all batch effects
show_other_data=True, # Show data points that do not match any batch effects
harmonize_data=True, # Set this to False to see the difference
show_legend=False, # Don't show the legend because it crowds the plot
);
Process: 29780 - 2026-04-22 16:03:25 - Synthesizing data for 1 response variables.
Process: 29780 - 2026-04-22 16:03:25 - Synthesizing data for Right-Amygdala.
Process: 29780 - 2026-04-22 16:03:25 - Dataset "centile" created.
- 150 observations
- 150 unique subjects
- 1 covariates
- 1 response variables
- 2 batch effects:
sex (1)
site (1)
Process: 29780 - 2026-04-22 16:03:25 - Computing centiles for 1 response variables.
Process: 29780 - 2026-04-22 16:03:25 - Computing centiles for Right-Amygdala.
Process: 29780 - 2026-04-22 16:03:25 - Harmonizing data on 1 response variables.
Process: 29780 - 2026-04-22 16:03:25 - Harmonizing data for Right-Amygdala.